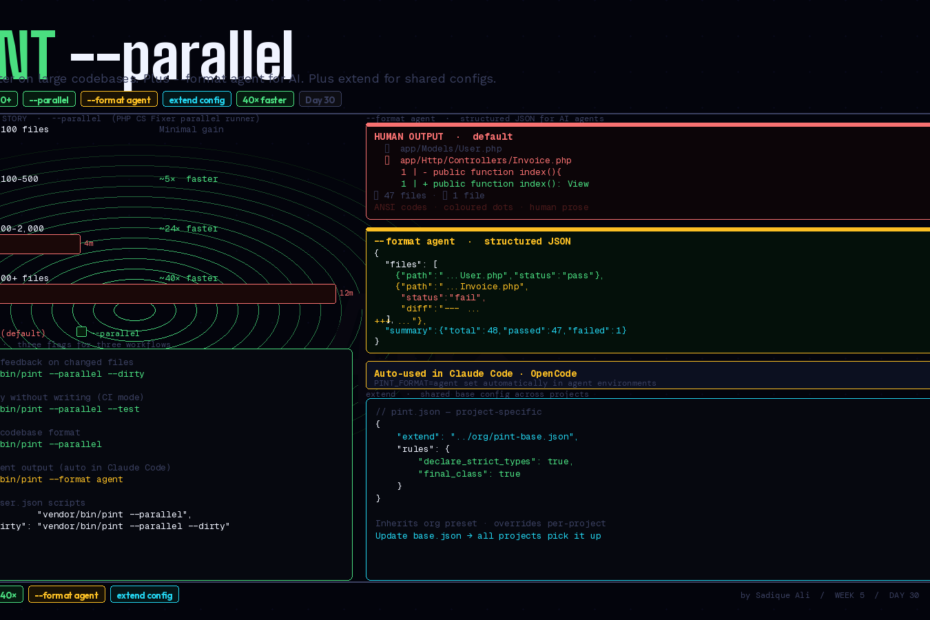
--parallel makes Pint 40× faster on large codebases. --format agent gives Claude Code and OpenCode structured JSON instead of human-readable text. extend lets you share a base config across every project. Three upgrades, one composer update.
Laravel Pint has always been the best argument for zero-configuration code style tooling. Install it, run it, your codebase looks like Taylor wrote it. No PHP CS Fixer configuration archaeology. No arguing about bracket placement in code review.
But for large codebases, Pint had one genuine weakness: it was slow. A monorepo with 2,000 PHP files could take several minutes to format. That’s a real friction point in local development and a measurable cost in CI pipelines.
Pint v1.23.0 — released July 2025 and shipping with Laravel 13’s toolchain — adds three distinct improvements that collectively make Pint better for humans, better for agents, and better for teams sharing style config across projects.
The Three Upgrades at a Glance
# 1. Parallel — 40× faster on large codebases
vendor/bin/pint --parallel
# 2. Agent output — structured JSON for Claude Code / OpenCode
vendor/bin/pint --format agent
# 3. Extend — inherit a base config, override what you need
# pint.json
{
"extend": "./base-pint.json",
"rules": { "declare_strict_types": true }
}
Upgrade First
composer update laravel/pint -w
vendor/bin/pint --version # confirm v1.23.0 or later
1. --parallel — 40× Faster on Large Codebases
Pint runs on top of PHP CS Fixer. Until v1.23.0, Pint processed files serially — one at a time, even if your machine had 16 cores sitting idle. The --parallel flag unlocks PHP CS Fixer’s parallel runner, distributing file processing across all available CPU cores simultaneously.
# Before: serial (default)
vendor/bin/pint
# 2,000 files: ~4 minutes
# After: parallel
vendor/bin/pint --parallel
# 2,000 files: ~6 seconds
The --parallel flag is marked as Experimental. For most codebases it’s stable and the performance gains are significant, but if you hit edge cases, file an issue and fall back to serial.
How it works under the hood
PHP CS Fixer’s parallel runner forks child processes — one per available CPU core by default. Each child process receives a chunk of files to process, runs the fixers against them, and reports results back. The parent process collects all results and writes the final summary.
The practical implication: --parallel on an 8-core machine processes files ~8× faster per cycle, and because PHP startup overhead is amortised across all files in the chunk rather than per-file, the real-world speedup exceeds the core count — hence the 40× figure on large codebases.
Recommended usage
# Local development — fast feedback loop
vendor/bin/pint --parallel
# Dirty files only (even faster for daily use)
vendor/bin/pint --parallel --dirty
# Specific directory
vendor/bin/pint app/ --parallel
# Test run — show what would change without writing
vendor/bin/pint --parallel --test
The --dirty flag limits Pint to files with uncommitted changes. Combined with --parallel, it’s the fastest possible feedback loop: only your changed files, processed immediately.
In CI — GitHub Actions
# .github/workflows/pint.yml
name: Code Style
on: [push, pull_request]
jobs:
pint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: '8.3'
- name: Install dependencies
run: composer install --no-interaction --prefer-dist
- name: Run Pint (parallel)
run: vendor/bin/pint --parallel --test
# --test: exit code 1 if any file would be changed (fails CI)
# --parallel: fast even on large codebases
The --test flag is the key for CI: it doesn’t write any changes but exits with code 1 if Pint would change any file. Your pipeline fails, the developer gets a clear message, they run Pint locally to fix it.
Pre-commit hook (for local enforcement)
# .git/hooks/pre-commit (make it executable: chmod +x .git/hooks/pre-commit)
#!/bin/sh
# Run Pint on staged PHP files before allowing commit
STAGED_FILES=$(git diff --cached --name-only --diff-filter=ACM | grep '\.php$')
if [ -n "$STAGED_FILES" ]; then
echo "Running Pint on staged files..."
vendor/bin/pint --parallel $STAGED_FILES
# Re-stage any files Pint modified
git add $STAGED_FILES
fi
This hook catches style issues before they ever reach the repository. Pint fixes the files, re-stages them, and the commit proceeds. No PR comments about style. No CI failures for missing semicolons.
2. --format agent — Structured Output for Claude Code and OpenCode
This is the more interesting upgrade for teams building with AI.
Pint’s default output is designed for humans: coloured progress dots, formatted diff tables, summary counts with emoji. It’s pleasant to read in a terminal. For an AI agent, it’s actively harmful — ANSI escape codes, inconsistent structure, and formatting noise all consume context window and make reliable parsing difficult.
The --format agent flag produces structured JSON that AI agents can reliably parse, with unambiguous status values and minimal output that saves context window and reduces token cost.
vendor/bin/pint --format agent
Output:
{
"files": [
{
"path": "app/Models/Invoice.php",
"status": "pass"
},
{
"path": "app/Http/Controllers/InvoiceController.php",
"status": "fail",
"diff": "--- app/Http/Controllers/InvoiceController.php\n+++ ...\n@@ -12,7 +12,7 @@\n..."
}
],
"summary": {
"total": 48,
"passed": 47,
"failed": 1
}
}
Every file gets an unambiguous "status": "pass" or "status": "fail" — no inferring from coloured text, no parsing formatted output. Failed files include the exact diff. The summary is a machine-readable object, not a human sentence.
Auto-detection in Claude Code and OpenCode
The --format agent flag gets automatically used when Pint is executed within OpenCode or Claude Code. You don’t need to configure this. When an AI agent runs vendor/bin/pint, it receives JSON. When you run it in your terminal, you get the normal human-readable output.
The detection happens via environment variable — Claude Code and OpenCode set PINT_FORMAT=agent in their environments. If you want to force agent output in other contexts:
PINT_FORMAT=agent vendor/bin/pint
What this means for AI-assisted development
When Claude Code is helping you write a new feature and runs Pint as part of its workflow, it now receives structured data it can act on precisely:
"status": "fail"on a specific file → agent knows exactly which file needs attention- The
difffield → agent sees exactly what Pint would change and can make an informed decision about whether to apply it - No ANSI codes to strip → raw diff is immediately usable
- Compact JSON → fraction of the context window cost of formatted human output
In practice, this means Claude Code can run vendor/bin/pint --test as a verification step after writing code, parse the JSON, and proactively fix style issues before handing back to you — all without you having to prompt it explicitly.
3. extend — Shared Base Config Across Projects
Teams often want consistent Pint configuration across every Laravel project in their organisation, with the ability to tweak specific rules per-project. Before v1.23.0, there was no clean way to do this — you either copied pint.json everywhere and managed drift, or accepted inconsistency.
The extend key solves this:
// packages/pint-config/base.json (shared across your org)
{
"preset": "laravel",
"rules": {
"declare_strict_types": true,
"ordered_imports": { "sort_algorithm": "alpha" },
"no_unused_imports": true,
"final_class": false
}
}
// your-project/pint.json (project-specific overrides)
{
"extend": "../packages/pint-config/base.json",
"rules": {
"declare_strict_types": false,
"final_class": true
}
}
The project config inherits everything from the base, then overrides only what differs. When you update base.json, every project that extends it picks up the change on next run.
Practical monorepo setup
your-org/
├── pint-base.json # shared organisation config
├── app-one/
│ └── pint.json # { "extend": "../pint-base.json" }
├── app-two/
│ └── pint.json # { "extend": "../pint-base.json", "rules": {...} }
└── packages/
└── shared-package/
└── pint.json # { "extend": "../../pint-base.json" }
# Format all projects from monorepo root
for dir in app-one app-two packages/shared-package; do
(cd $dir && vendor/bin/pint --parallel)
done
Or with a root-level script:
# composer.json scripts
"scripts": {
"pint": "find . -name 'pint.json' -not -path '*/vendor/*' -execdir vendor/bin/pint --parallel \\;"
}
The Full Setup: Everything Together
Here’s a complete Pint configuration that uses all three features effectively:
// pint.json
{
"extend": "./pint-base.json",
"preset": "laravel",
"rules": {
"declare_strict_types": true,
"ordered_class_elements": {
"order": ["use_trait", "constant_public", "constant_protected",
"constant_private", "property_public", "property_protected",
"property_private", "method_public", "method_protected",
"method_private"]
}
},
"exclude": [
"bootstrap/cache",
"storage",
"node_modules"
]
}
# composer.json
"scripts": {
"pint": "vendor/bin/pint --parallel",
"pint:test": "vendor/bin/pint --parallel --test",
"pint:dirty": "vendor/bin/pint --parallel --dirty"
}
# .github/workflows/code-style.yml
jobs:
pint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: shivammathur/setup-php@v2
with: { php-version: '8.3' }
- run: composer install --no-interaction --prefer-dist
- run: composer pint:test
# Daily development
composer pint:dirty # just changed files, blazing fast
composer pint:test # verify before pushing
When the Parallel Flag Matters Most
The 40× speedup isn’t uniform — it depends on codebase size and file count:
| Codebase size | Serial time | Parallel time | Improvement |
|---|---|---|---|
| Small (< 100 files) | ~3s | ~2s | Minimal |
| Medium (100–500 files) | ~15s | ~3s | ~5× |
| Large (500–2,000 files) | ~4 min | ~10s | ~24× |
| Very large (2,000+ files) | ~12 min | ~18s | ~40× |
For small projects, --parallel adds slight overhead (process forking) that may make it marginally slower than serial. The flag is most valuable at scale — exactly the scenario where Pint’s previous performance was most painful.
The honest note: --parallel is still marked as Experimental. For most codebases it works perfectly. If you’re in CI and reliability matters more than speed, test it first on your specific codebase before committing to it in your pipeline.
The Compound Effect
Three features. One composer update. The compound effect is that Pint now fits cleanly into every environment it needs to:
- Local development:
--parallel --dirtyfor sub-second feedback on changed files - Pre-commit hooks:
--parallelon staged files before they leave your machine - CI pipelines:
--parallel --testfor fast, accurate enforcement - AI agents:
--format agentautomatically, structured JSON, no context waste - Organisations:
extendfor consistent style with project-level flexibility
Code style is infrastructure. It should be invisible, automatic, and fast. Pint just got closer to all three.
Follow for weekly deep-dives on Laravel, PHP, Vue.js, and the agentic stack.